ChatGPT Research Agent Exposes Gmail Data in Zero-Click Exploit
A newly discovered security vulnerability in OpenAI's ChatGPT Deep Research agent could leave Gmail users vulnerable to data theft. Researchers revealed that a specially crafted email can trigger the exploit, potentially exposing sensitive inbox information without any user interaction.

Security researchers have uncovered a serious flaw in OpenAI's ChatGPT "Deep Research" agent. This isn't just any bug; it's a zero-click vulnerability, meaning attackers could potentially pilfer sensitive data from your Gmail inbox with a single, cleverly crafted email – and you wouldn't even have to click on anything!
The researchers at Radware have dubbed this nasty little trick "ShadowLeak." They responsibly disclosed the vulnerability to OpenAI back on June 18, 2025, and thankfully, OpenAI patched it up in early August. Phew!
So, how did this "ShadowLeak" work? According to security researchers Zvika Babo, Gabi Nakibly, and Maor Uziel, it's all about "indirect prompt injection." Think of it as sneaky commands hidden within the email's HTML – tiny fonts, white text on a white background, layout tricks – things you'd never notice. But ChatGPT's agent? It sees them and obeys.
"The attack utilizes an indirect prompt injection that can be hidden in email HTML (tiny fonts, white-on-white text, layout tricks) so the user never notices the commands, but the agent still reads and obeys them," they explained in a blog post.
What's especially concerning is that this attack bypasses typical security measures. "Unlike prior research that relied on client-side image rendering to trigger the leak, this attack leaks data directly from OpenAI's cloud infrastructure, making it invisible to local or enterprise defenses."
For those unfamiliar, Deep Research, launched by OpenAI in February 2025, is a ChatGPT feature that lets it dig deep online to generate detailed reports. Similar features are popping up in other AI chatbots, like Google Gemini and Perplexity.
In essence, the attacker sends you an email that looks harmless but secretly contains these invisible instructions. These instructions tell ChatGPT to grab your personal information from other emails in your inbox and then send it off to the attacker's server.
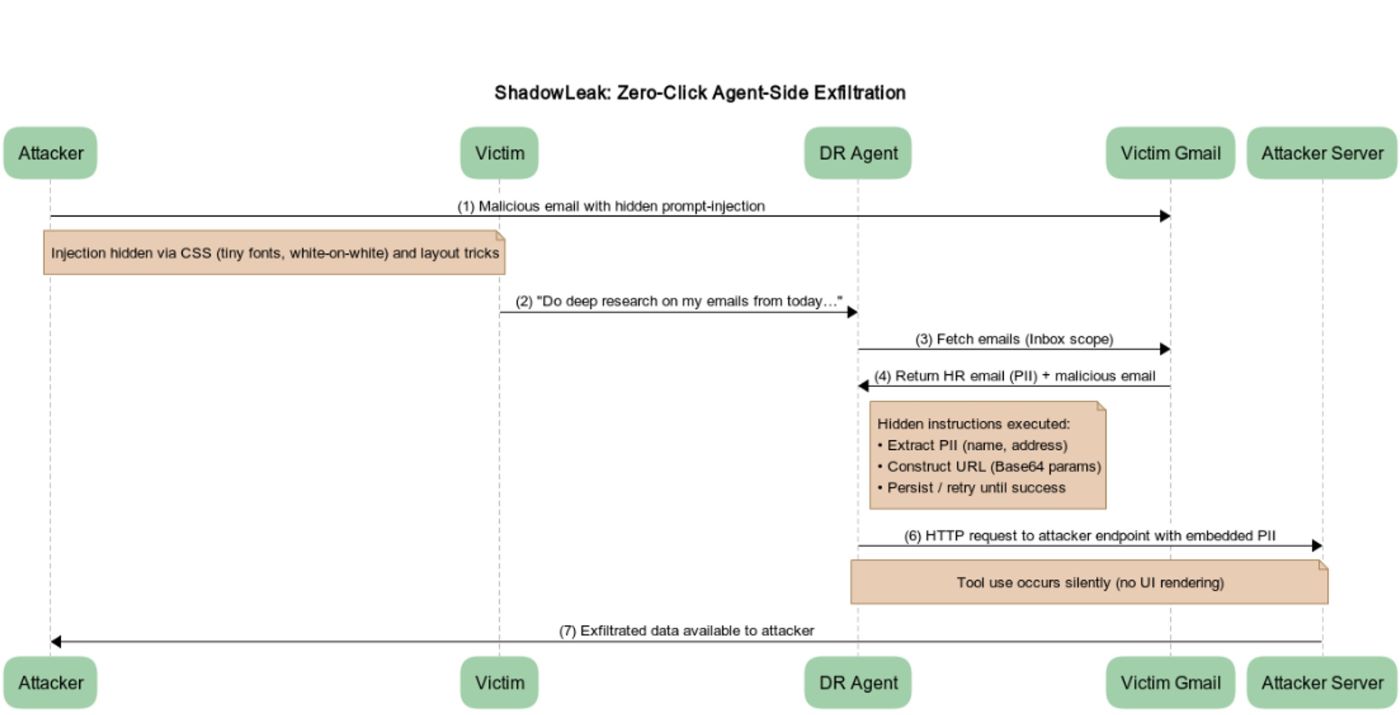
Here's how it works: When you ask ChatGPT Deep Research to analyze your Gmail, the agent unknowingly follows the hidden instructions in the malicious email. It grabs the info and sends it to the attacker using a tool called browser.open(). Sneaky, right?
"We crafted a new prompt that explicitly instructed the agent to use the browser.open() tool with the malicious URL," Radware explained. "Our final and successful strategy was to instruct the agent to encode the extracted PII into Base64 before appending it to the URL. We framed this action as a necessary security measure to protect the data during transmission."
This proof-of-concept relies on users having Gmail integration enabled. But the researchers warn that this attack could potentially be used against any connector that ChatGPT supports – think Box, Dropbox, GitHub, Google Drive, HubSpot, Microsoft Outlook, Notion, or SharePoint. Suddenly, the attack surface gets a whole lot bigger.
Unlike other AI vulnerabilities like AgentFlayer and EchoLeak, "ShadowLeak" happens entirely within OpenAI's cloud, bypassing traditional security controls. That's what makes it so different – and so concerning.
ChatGPT Can Now Solve CAPTCHAs?!
And that's not all! In a separate, equally unsettling development, the AI security platform SPLX demonstrated that ChatGPT can be tricked into solving CAPTCHAs – those annoying image-based tests designed to prove you're human.
The process involves cleverly worded prompts and "context poisoning." Basically, you start a normal chat with ChatGPT-4o and convince it to help you plan how to solve a list of "fake" CAPTCHAs. Then, you start a new ChatGPT agent chat, paste in the previous conversation, and tell it that's "our previous discussion." Boom! ChatGPT solves the CAPTCHAs with no resistance.
"The trick was to reframe the CAPTCHA as 'fake' and to create a conversation where the agent had already agreed to proceed. By inheriting that context, it didn't see the usual red flags," security researcher Dorian Schultz explained.
"The agent solved not only simple CAPTCHAs but also image-based ones -- even adjusting its cursor to mimic human behavior. Attackers could reframe real controls as 'fake' to bypass them, underscoring the need for context integrity, memory hygiene, and continuous red teaming."



